Quickture’s geavanceerde transcriptieservice herkent sprekers beter dan alle andere aanbieders, en voorspelt automatisch hun namen zodat je labels supersnel klaar zijn! In onze tests raadt Quickture de namen van de spreker in ongeveer 80% van de gevallen goed.
Als Quickture een spreker niet kan herkennen, krijgt die het label Unknown en moet jij de labels voor de overgebleven sprekers invullen. Klik op het label van de spreker (in het voorbeeld hieronder, Spreker 8) om direct naar de eerste zin van die spreker te springen, speel het fragment af en bevestig de naam van de spreker.

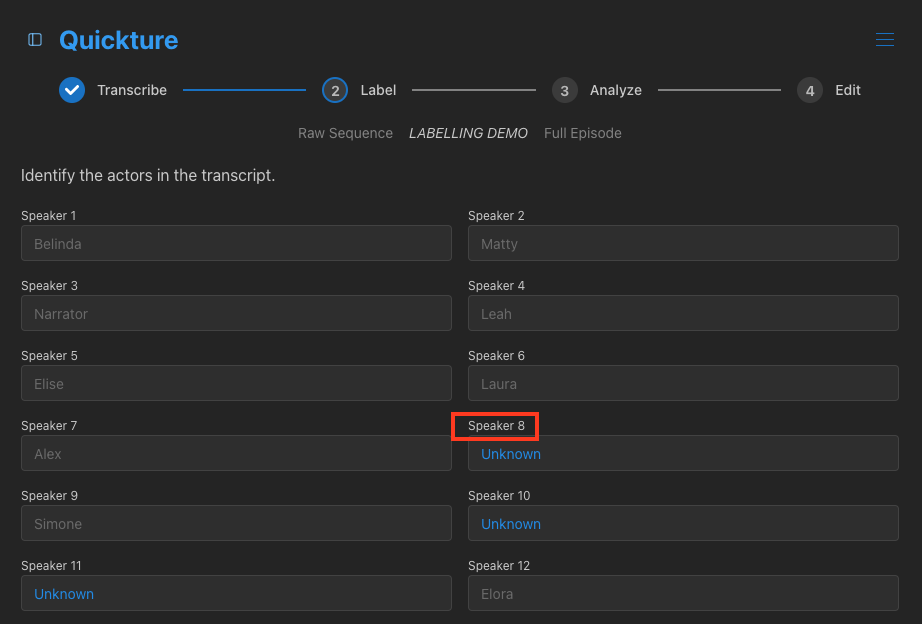
Soms splitst Quickture per ongeluk één spreker in tweeën. Bijvoorbeeld als regels van je geïnterviewde Nancy onder zowel Spreker 1 als Spreker 2 worden gezet. In zo'n geval geef je beide sprekers gewoon het label "Nancy" om het transcript te corrigeren.
Quickture slaat automatisch allerlei transcript-bestanden op je computer op elke keer dat je een sequence transcribeert. Standaard worden ze hier opgeslagen:
Quickture Avid Paneel: in je Avid projectmap, in een submap genaamd Quickture Data.
Quickture Premiere Paneel: in je Premiere projectmap, in een submap genaamd ProjectName Quickture Exports.
Quickture Avid Standalone: Gebruiker > Documenten > Quickture > Project
Ter info: de Quickture Data of Quickture Exports map bevat ook de wav en mp3's die we maken om je sequenties te transcriberen.
Je kunt zelf bepalen welke soorten transcript-bestanden worden opgeslagen en waar, via de Transcriptvoorkeuren in het hamburgermenu rechtsboven in de app.
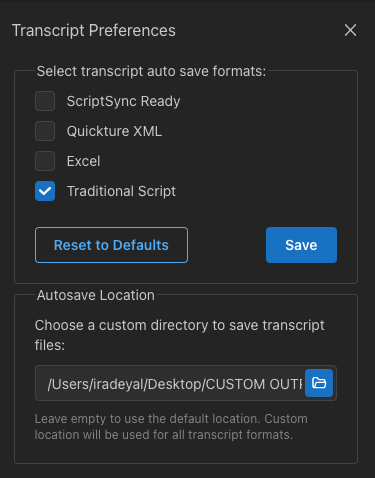
ScriptSync Ready - Een .txt-bestand met timecode, spreker en dialoog per regel. Dit bestand is perfect om te importeren in Script Sync.
Quickture XML - Dit is Quickture’s formaat om een transcript en de losse beats te omschrijven. Je kunt dit transcript of delen ervan plakken in een Quickture prompt en Quickture snapt het formaat meteen.
Excel - Een Excel-bestand met kolommen voor beatbeschrijving, tijdcode, spreker en tekst—handig om makkelijk naar andere formaten om te zetten.
Traditional Script - Dit is een .txt-bestand met regels die in overzichtelijke alinea’s staan. Als een spreker meerdere regels achter elkaar heeft, voegen we deze samen zonder de spreker steeds opnieuw te noemen.
Klik op het map-icoon om een andere opslaglocatie voor je transcripts te kiezen.